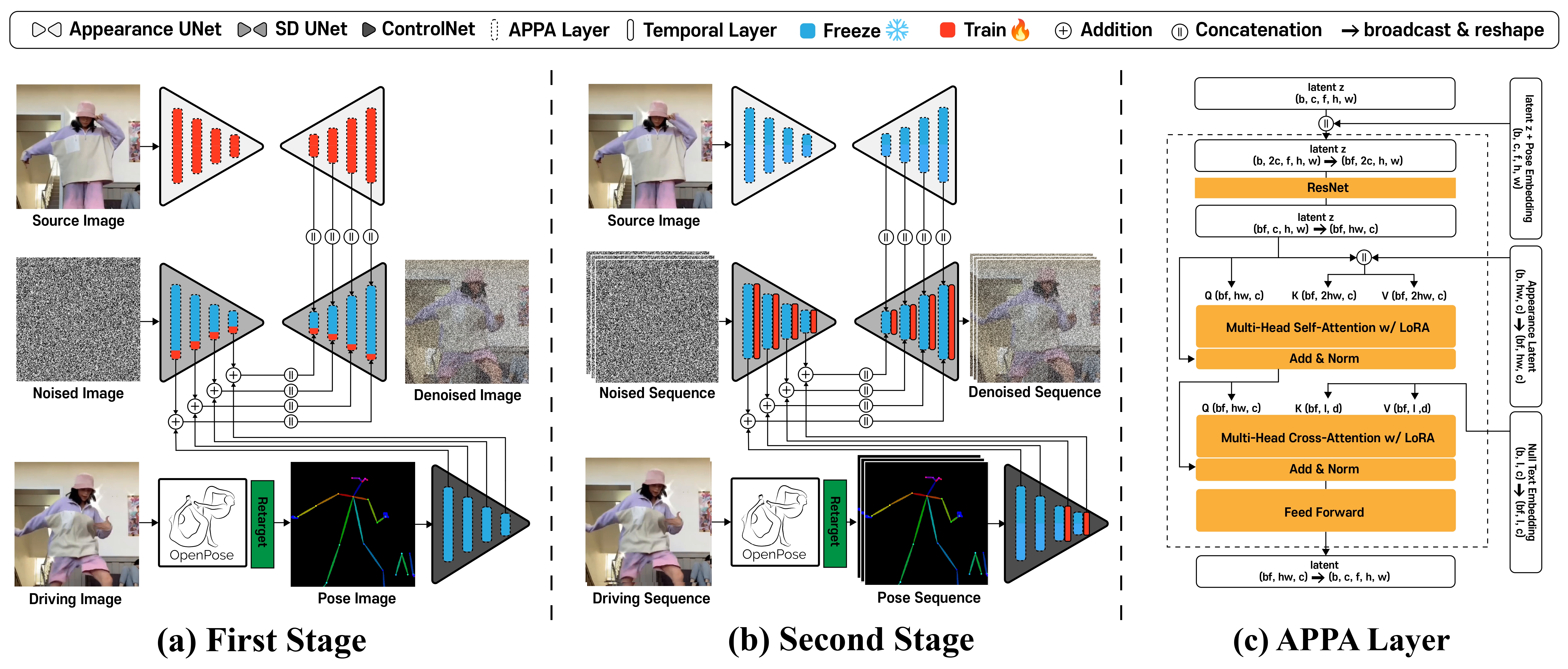
Given a source image and a driving video with F frames, our aim is to generate a video that:
Incorporating the foreground appearance from the source image.
Following the pose of the driving video.
Maintaining consistency in the background of the source image.
Our approach
We propose TCAN, a novel human image animation framework based on the diffusion model that maintains temporal consistency and generalizes well to unseen domains. Our newly proposed modules are as follows:
Appearance-Pose Adaptation (APPA layer): Preserving the appearance of the source image while maintaining pose information from frozen ControlNet.
Temporal ControlNet: Preventing the generated video from collapsing due to abrupt and erroneous pose changes
Pose-driven Temperature Map: Reducing the flickering in the static region by smoothing the attention scores in the temporal layer at the inference stage.